
[Sitecore 8][Content Search][IFilter]IFilterを使ってサイトコアコンテンツ検索その三、Adobe Ifilter 9を使ってリファレンスフィールドにあるPDFファイルのコンテンツを検索
概要:AdobeIFilter9を使って、リファレンスフィールドにあるPDFファイルのコンテンツのインデックスをする手順を書きます。
検証環境は次の通りです。
- Sitecore 8
- Sitecore 7x
課題
前回ではAdobeIFilter9を使って、メディアファイルがインデックスすることを確認しました。
ただ、これはディフォルトでファイルがメディアライブラリにあります。特定のアイテムにてファイルファイルを使用する場合、そのファイルフィールドで指定しているPDFファイルのコンテンツをインデックスすることカスタムインデックスフィールドが必要になります。
今回その手順を書きます。
下準備
検証用にファイルフィールとを追加します。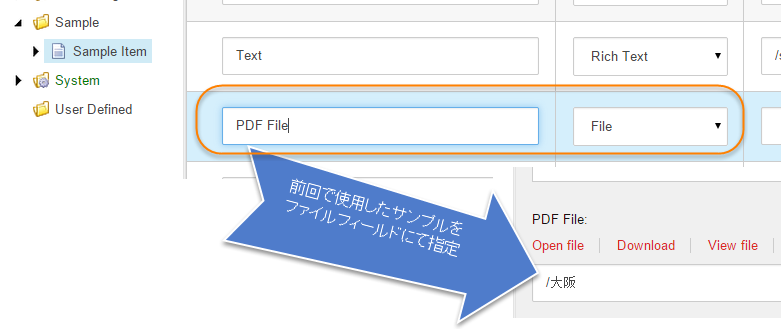
手順
Sitecore.ContentSearch.Lucene.DefaultIndexConfiguration.configにて、_contentフィールドの抽出設定がありますそれをまねに独自のカスタムフィールドを定義して、PDFのコンテンツを抽出するのです。
1.独自のMediaItemIFilterTextExtractorを定義します。
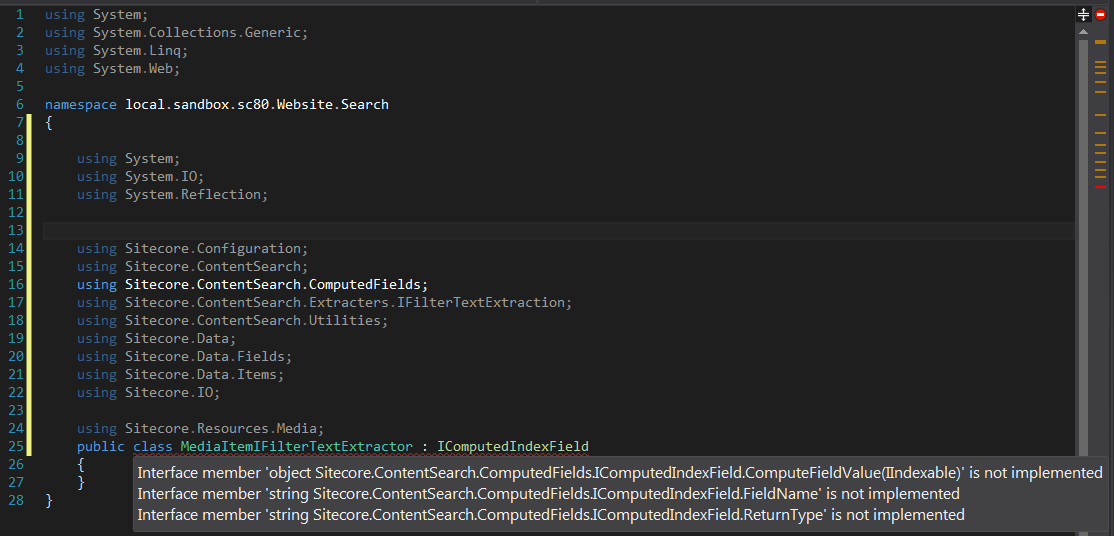
2.必要な関数を追加
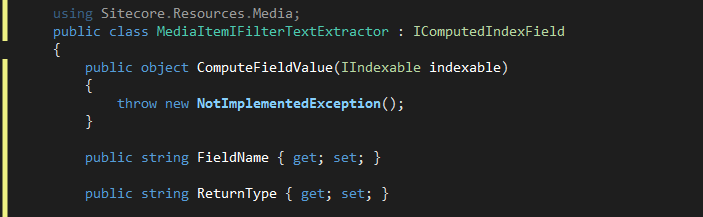
3.PDFのコンテンツを抽出するコードはこのクラスをライブラリよりコピーします。 Sitecore.ContentSearch.ComputedFields.MediaItemIFilterTextExtractor
コートはそのままコピーすればいいですのであえてここで掲載しません。ただ、変更するのは一箇所です。メディアアイテムをする代わりに、ファイルフィールでしてしているメディアに切り替えることで、抽出したコンテンツをカスタムフィールドにてインディクスします。
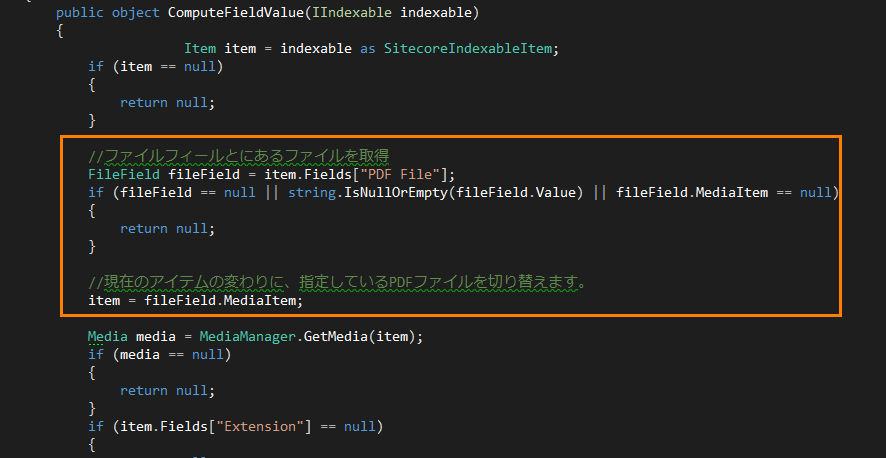
4.クラスを追加した後、カスタムフィールドの定義をしましょう。
*この設定をパッチConfigとして、追加するのは普通です。また、パッチconfigのフィル名は”z”出始めましょう。その理由はイトコアはWeb.configファイルをアルファベット順にインクルードファイルを処理します。”z”でファイル名を始めれば別の.configにオーバーライドされなくでも済むからです。
今回、Sitecore.ContentSearch.Lucene.DefaultIndexConfigurationに直接追加することにします。追加する場所は二箇所です。
まず、抽出するメディアのタイプを有効、この場合はPDFです。
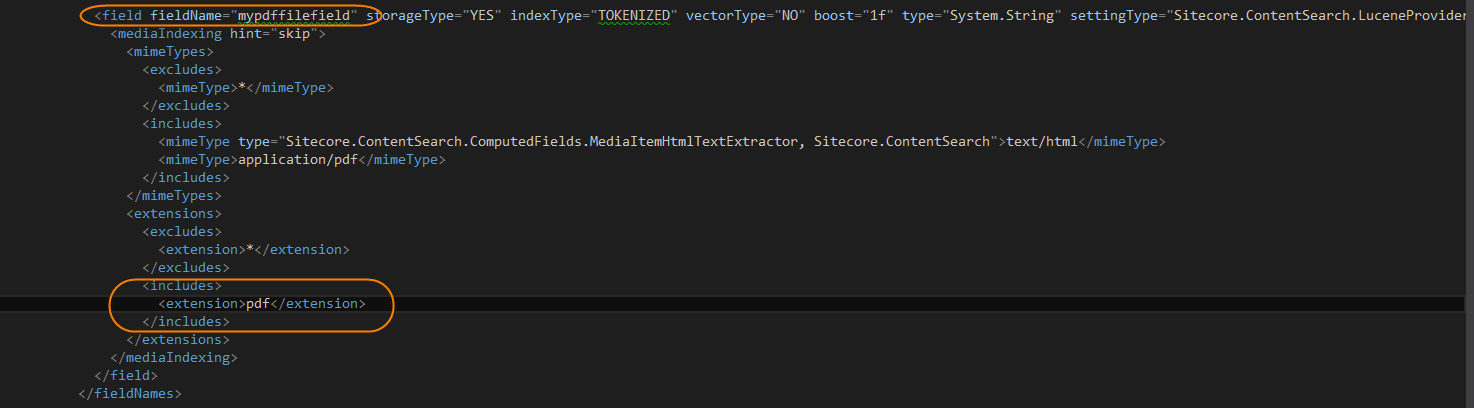
次に、カスタムフィールドを追加し、抽出するクラスを指定。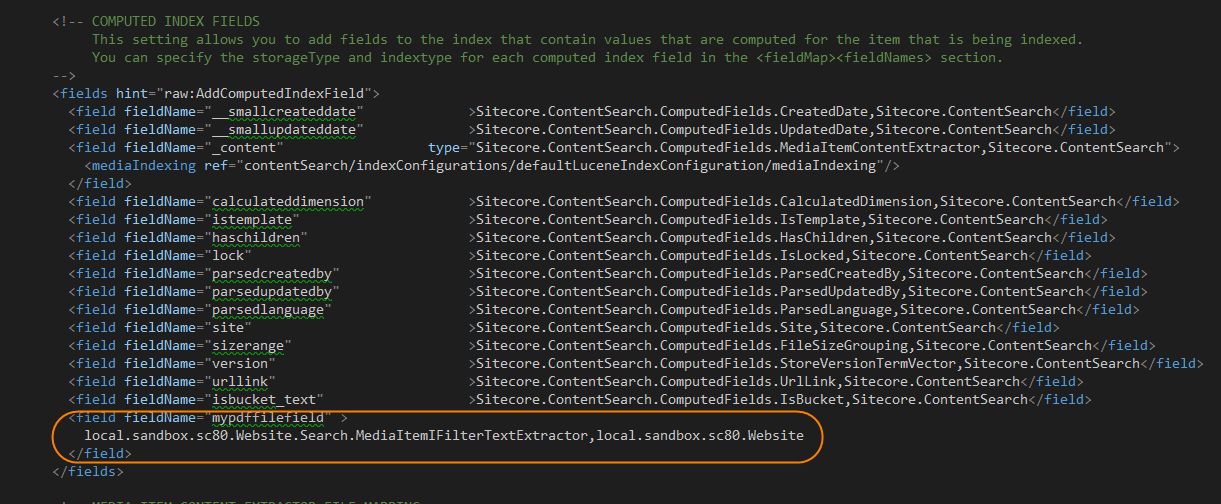
前回のAdobe Ifilter 9を使ってコンテントをインデックスの手順7に従います。

確認
ukeを使って、抽出したフィールド “mypdffilefield” にてPDFのコンテンツを確認。Lukeを使ってサイトコア8のLucenceインデックスの内容を確認する方法はこの記事を参考
